
前言
为什么要本地部署?
- 数据仅在本地处理,不会上传云端。
- 不受某些神秘的限制。
- 更快地响应输出。
- 不依赖互联网连接,可以无网络使用。
- 可以根据具体需求对模型进行微调和优化,以适应特定的应用场景。
- 可以快速响应和解决技术问题,减少对外部支持的依赖。
Ollama安装
什么是Ollama?
Ollama 是一个用于在本地运行大型语言模型(LLMs)的工具。它允许用户在个人计算机上部署和运行各种开源语言模型,如 LLaMA、Mistral 等。Ollama 提供了一个简单的命令行界面,使得用户能够轻松地下载、管理和与这些模型进行交互。
首先打开Ollma官网↗,下载跟你系统对应的Ollma版本。 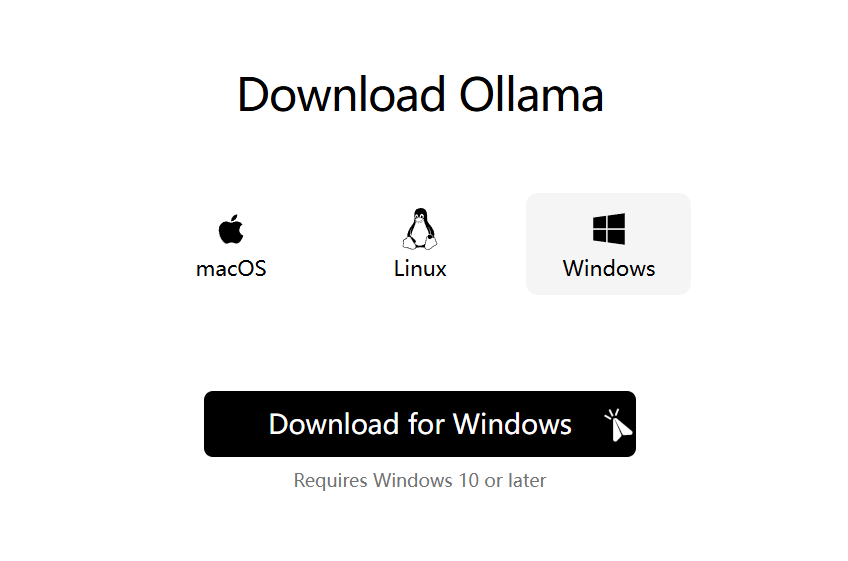 下载好后点击
下载好后点击Install安装即可。
下载慢的话可以点击这里↗使用我的huang1111网盘进行下载。 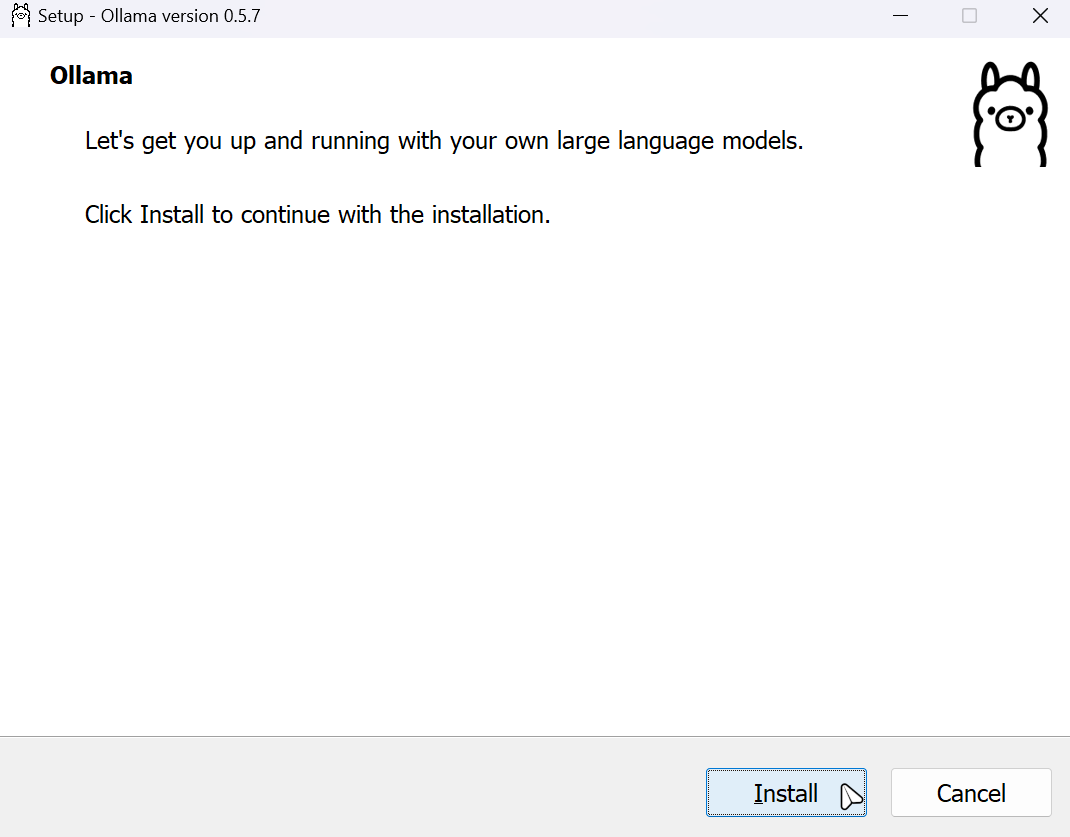 打开命令提示符或PowerShell均可,输入
打开命令提示符或PowerShell均可,输入ollama,如果出现我这样的信息,就证明Ollama成功安装了。 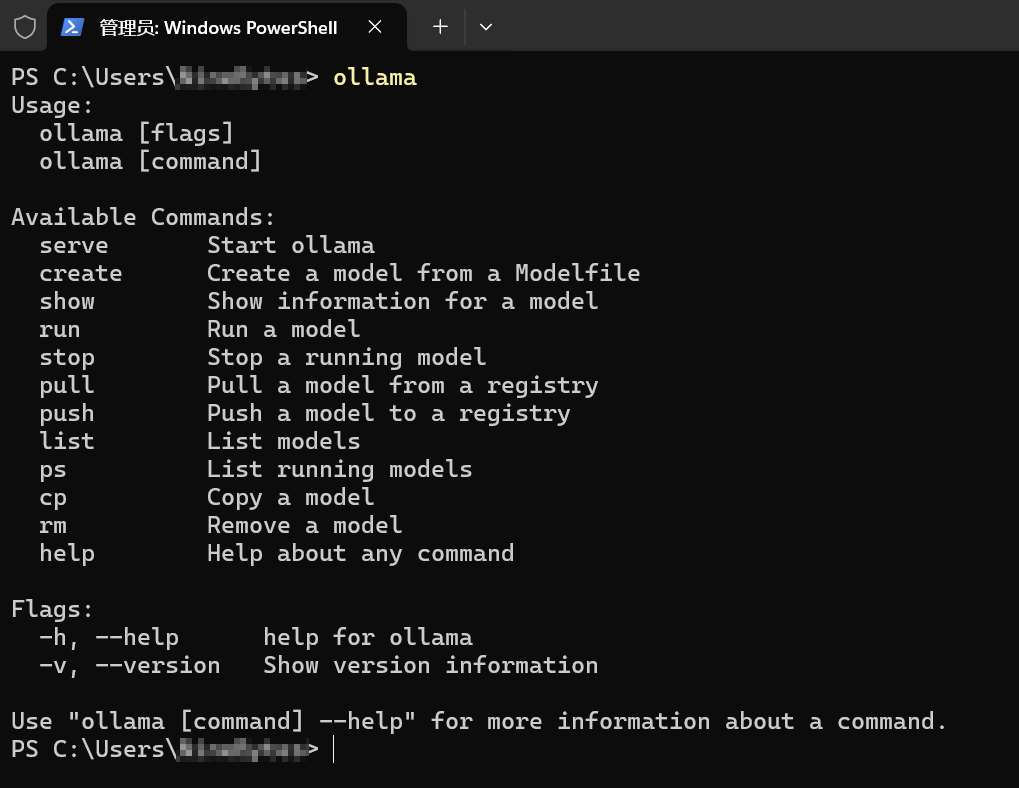
寻找合适版本
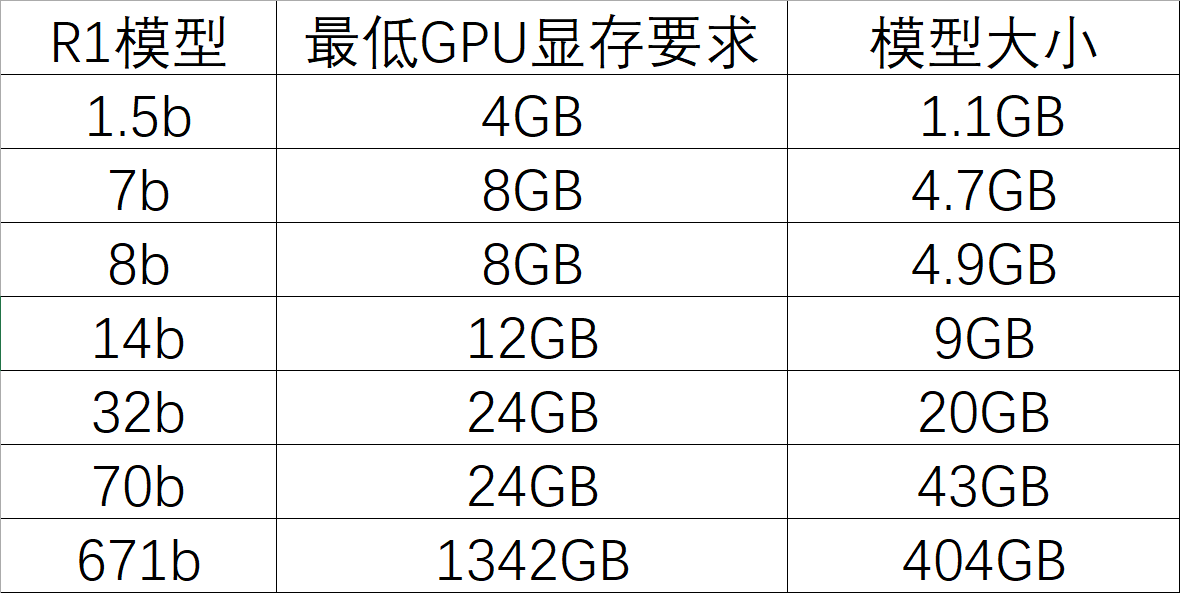
再次打开Ollma官网↗,在搜索框内输入deepseek,点击deepseek-r1。 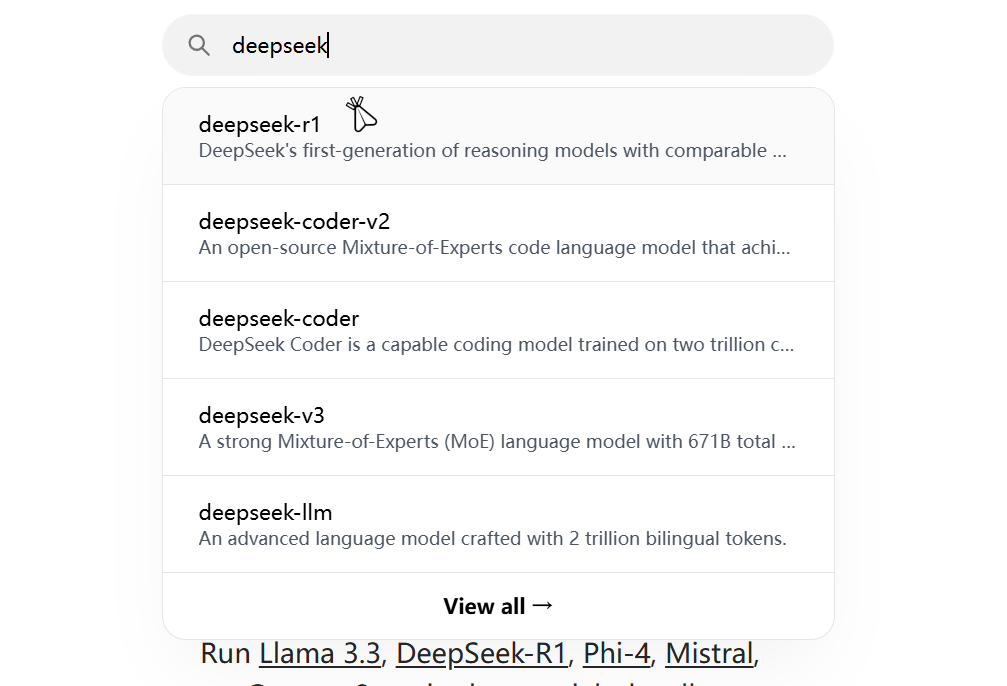 这里提供了多个蒸馏过的R1模型,根据自己电脑配置进行选择。
这里提供了多个蒸馏过的R1模型,根据自己电脑配置进行选择。
- Tips:1.5b核显也可以运行
 下面是各个版本的运行命令:
下面是各个版本的运行命令:
1.5b:
ollama run deepseek-r1:1.5b7b:
ollama run deepseek-r1:7b8b:
ollama run deepseek-r1:8b14b:
ollama run deepseek-r1:14b32b:
ollama run deepseek-r1:32b70b:
ollama run deepseek-r1:70b671b:
ollama run deepseek-r1:671b我的显卡是4060L,有8GB的显存,运行8b模型即可。
将命令复制后,打开命令提示符或PowerShell,然后将命令粘贴进去然后回车即可。耐心等待下载完成。 
运行DeepSeek
下载完成后,命令行内输入ollama list查看已经下载好的模型。
使用ollama run model_name运行对应的模型。 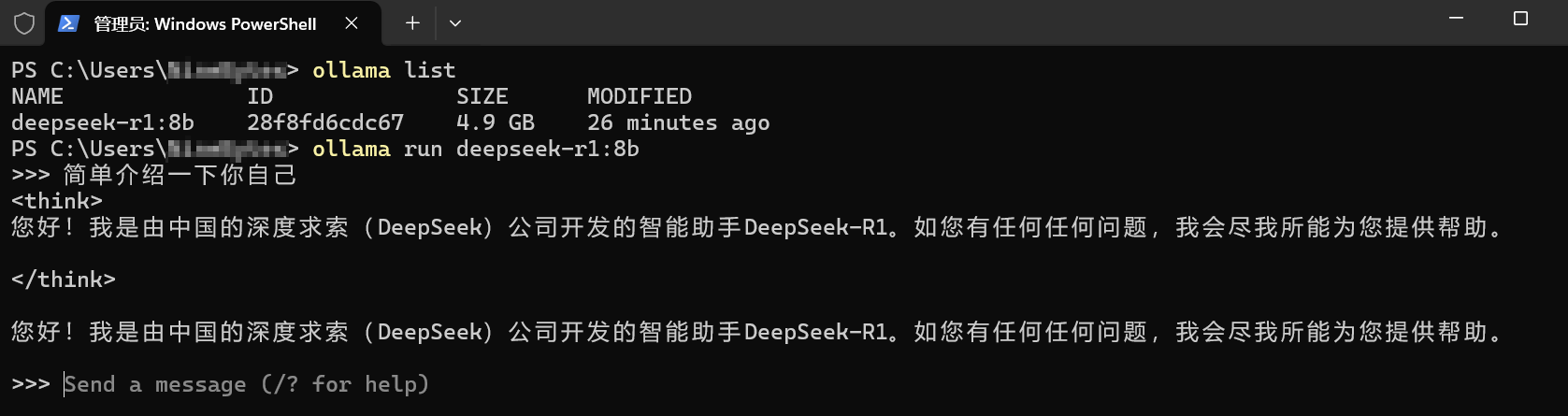
安装ChatBox
访问ChatBox官网↗,点击免费下载(for Windows)下载ChatBox,然后安装。
下载慢的话可以点击这里↗使用我的huang1111网盘进行下载。  安装完成后打开ChatBox,第1次打开会让你选择并配置AI模型提供方。点击
安装完成后打开ChatBox,第1次打开会让你选择并配置AI模型提供方。点击使用我自己的API KEY或本地模型。 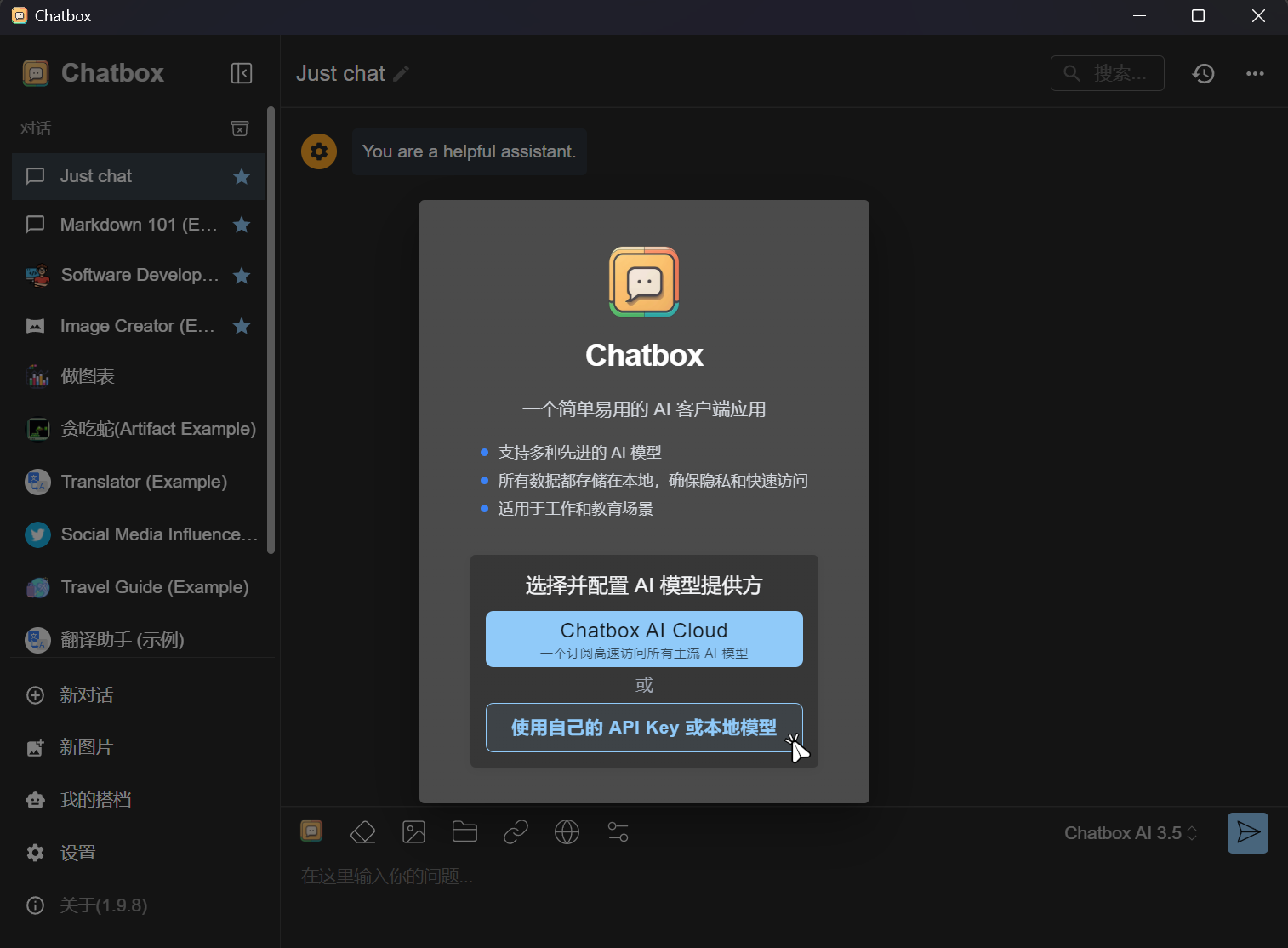
配置ChatBox
点击Ollama API。 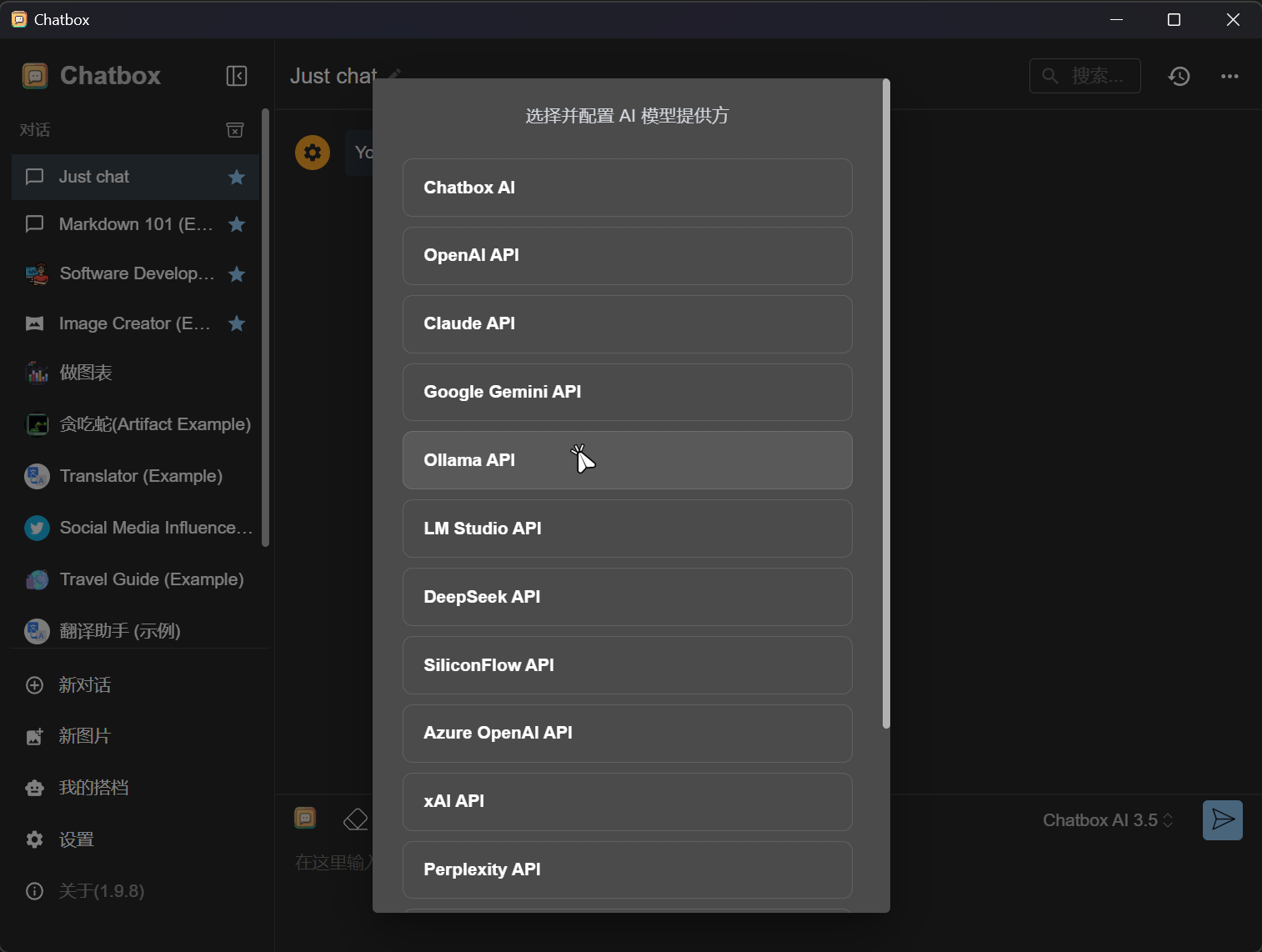 选择本地DeepSeek模型。
选择本地DeepSeek模型。 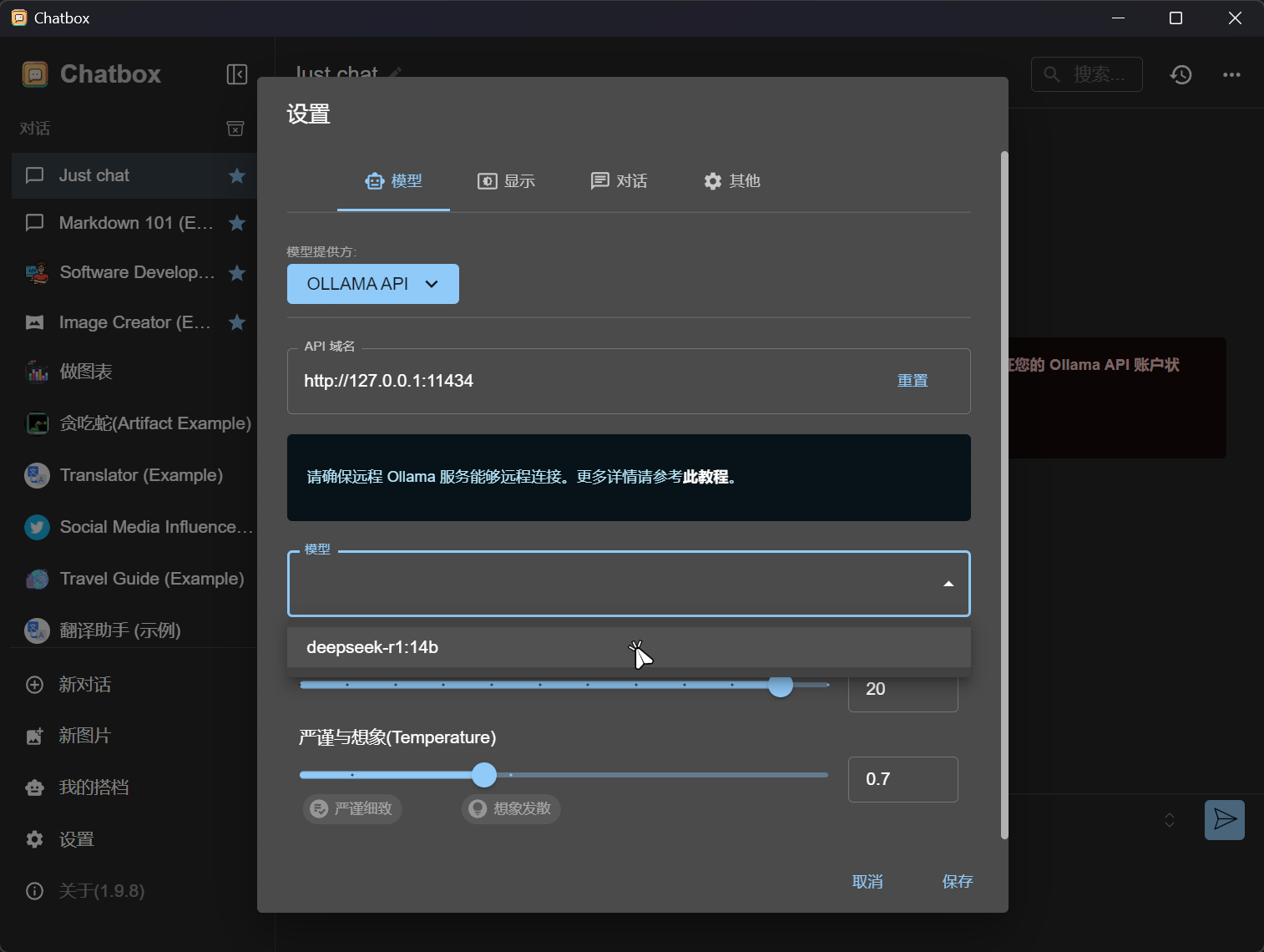 点击保存。
点击保存。 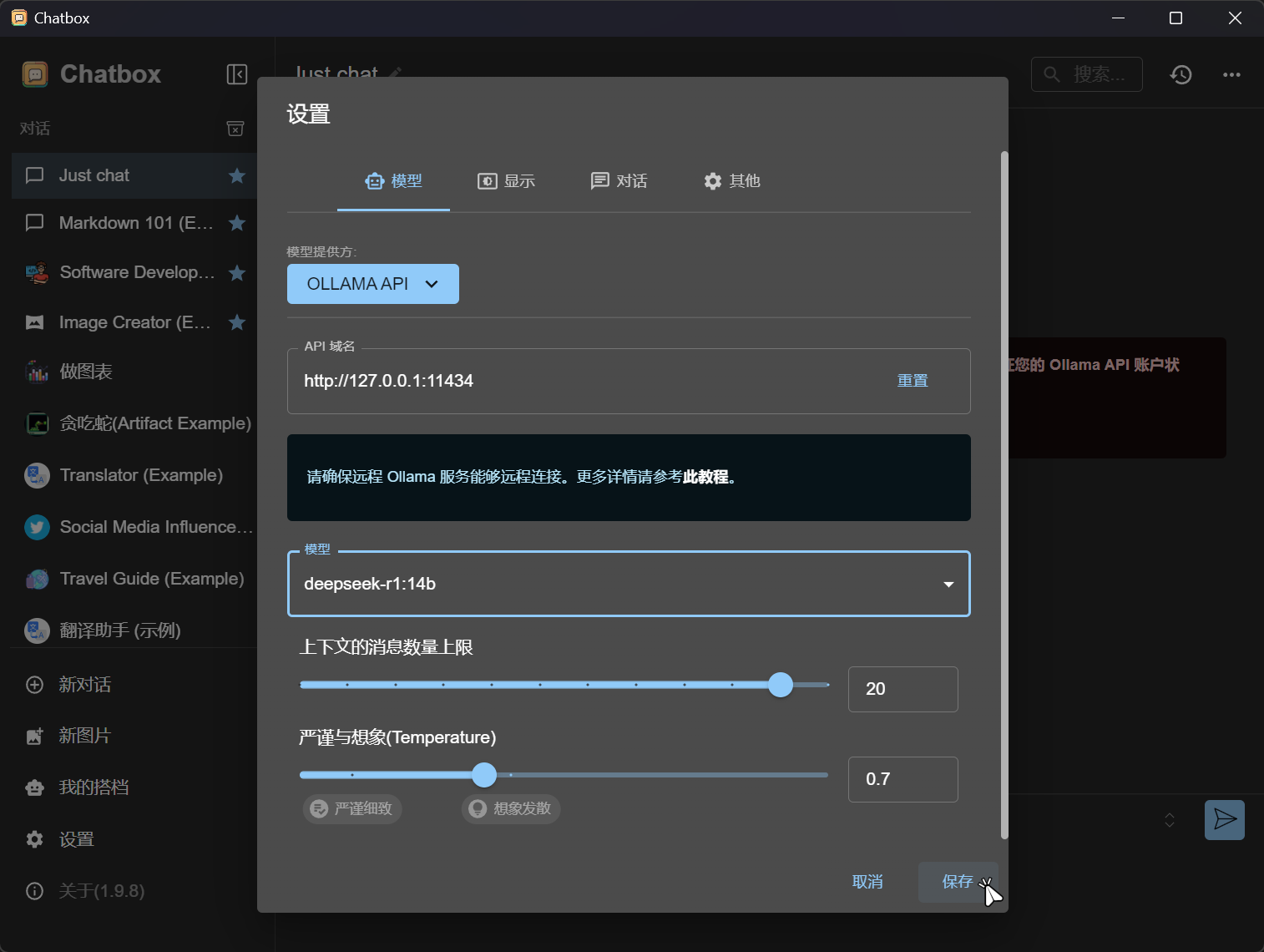 即可开始使用图形化界面。
即可开始使用图形化界面。 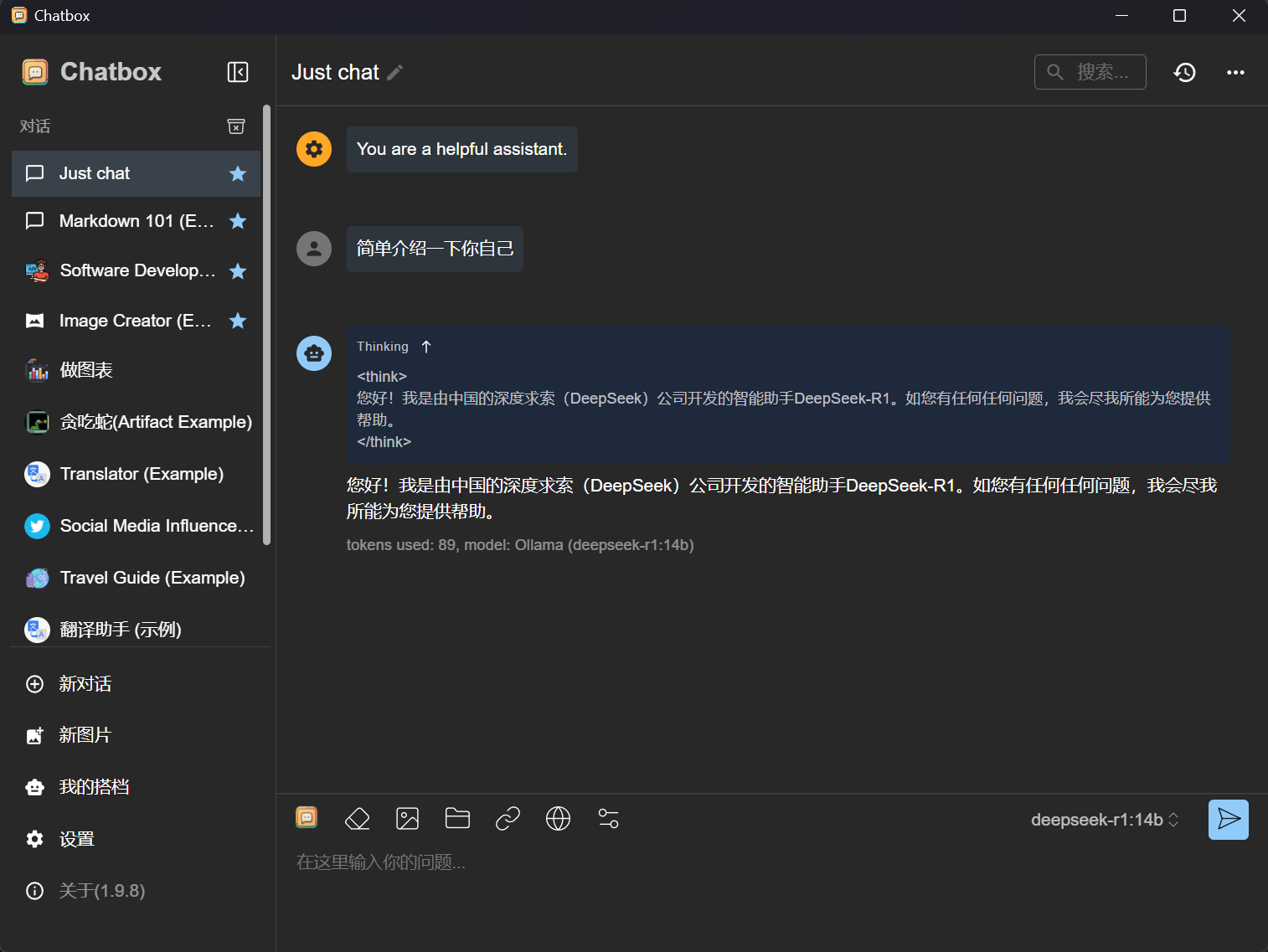
使用Web UI
由于需要Magic环境,我并没有Magic,所以没有配图,只有文本。
- 使用Google Chrome安装Page Assist↗插件后,启动Ollama服务。
- 在Google Chrome内使用快捷键Ctrl + Shift + L即可呼出Page Assist页面。
- 首次打开需要简单配置一下:在右上角设置-RAG Setting中选择为你下载的DeepSeek模型,然后回到对话窗口,即可在WebUI中玩耍了。
卸载模型
使用命令ollama rm model_name来卸载模型。 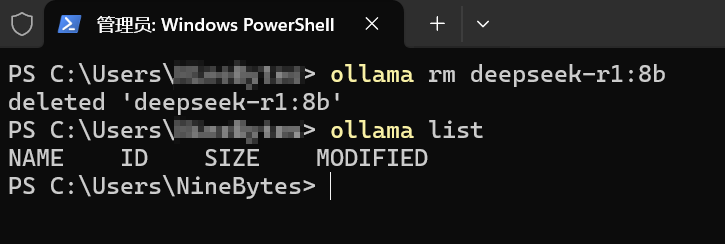
最后
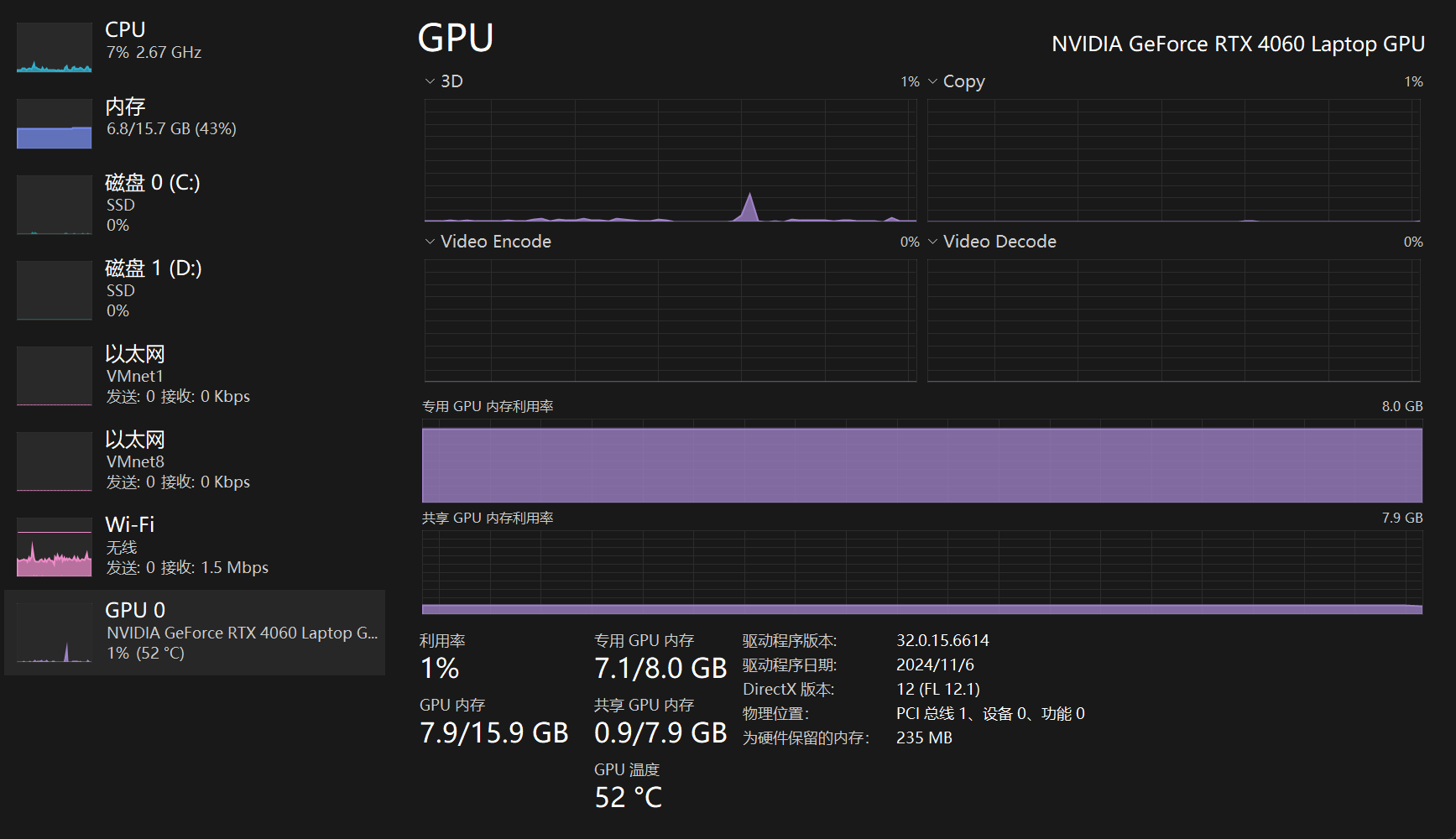
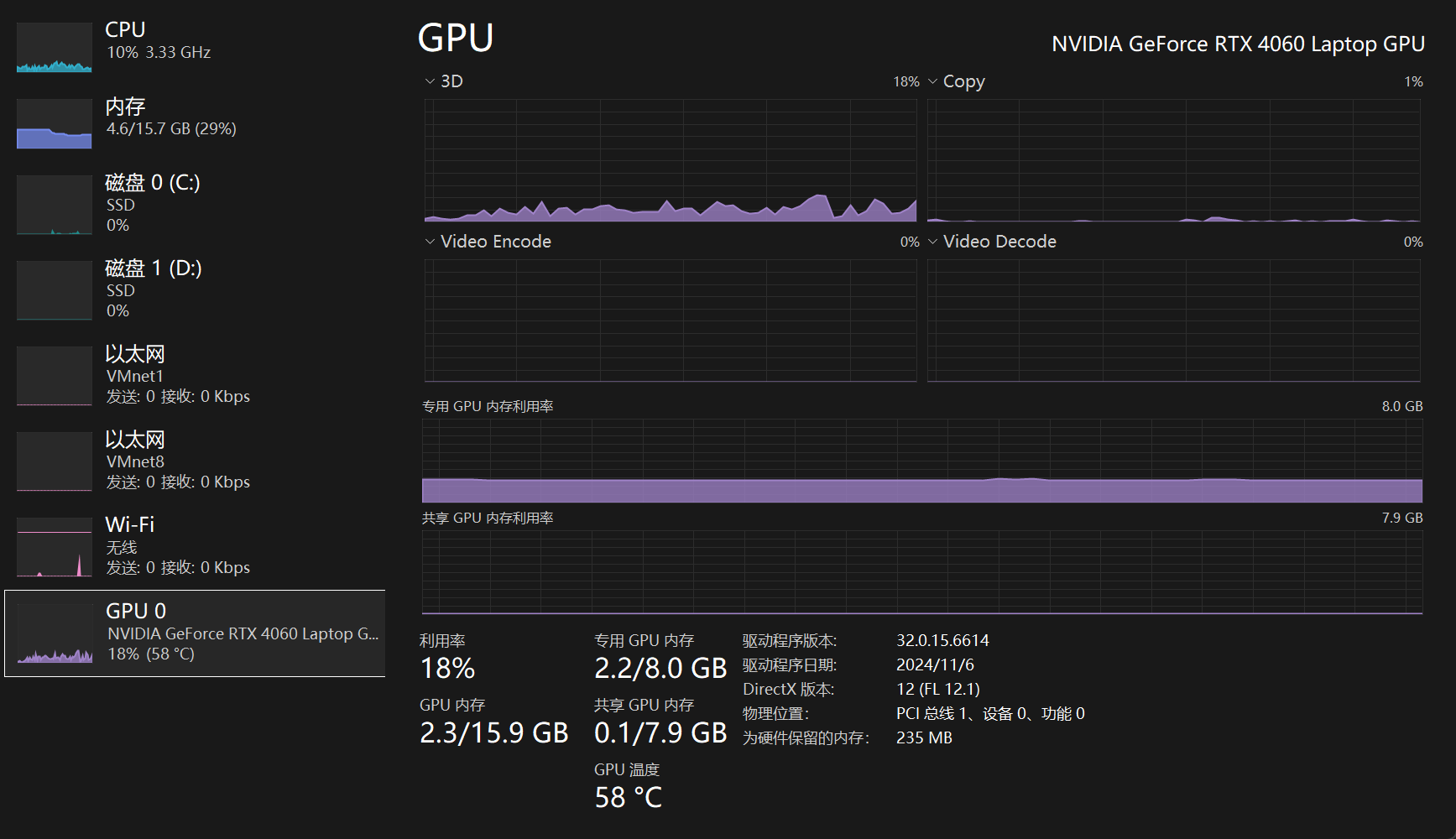
运行8b模型前后时的显存占用图。
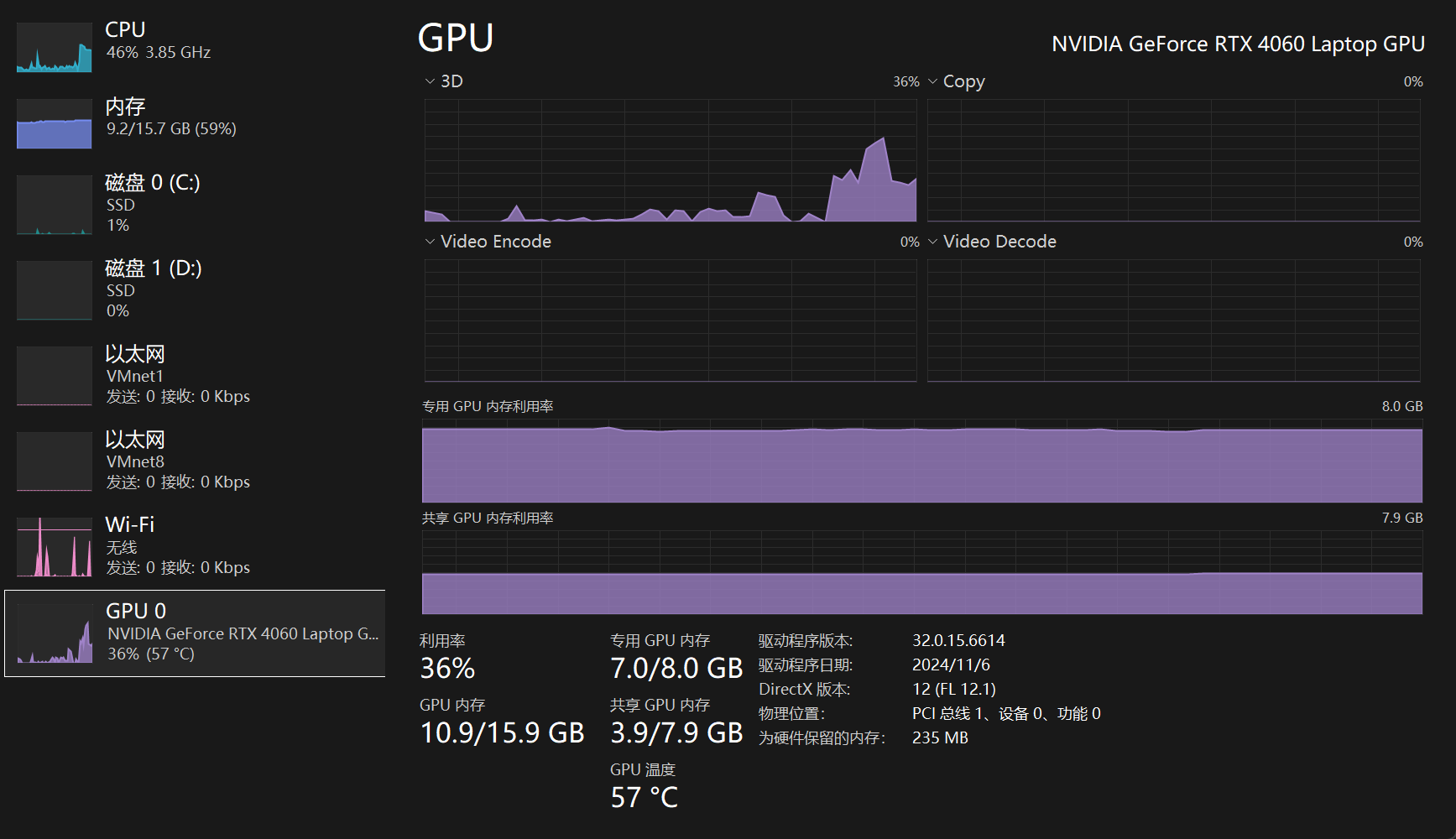
运行14b模型前后时的显存占用图。
- Tips:如果下载到最后特别慢的话,可以Ctrl + C停止后,再次执行该运行命令。